Вопросы на собеседовании Senior Node.JS разработчику
Написал на медиуме небольшой пост про базовые вопросы к Senior Node.JS разработчику на собеседовании.
Написал на медиуме небольшой пост про базовые вопросы к Senior Node.JS разработчику на собеседовании.
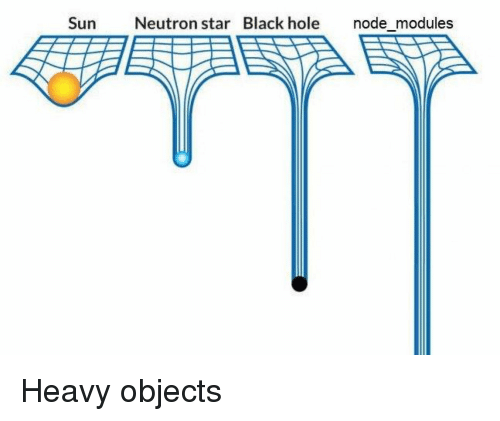
Наверняка вы часто замечали, сколько всякого мусора лежит внутри node modules. Это тесты, бенчмарки, ридми файлы, лицензии, тайпскрипт, и ещё безумное количество мусора, который можно более-менее безопасно удалить. Что мы собственно и сделаем в этом посте. Картинку про вес node module я и так упоминал последние несколько публикаций, так что вот вам другая, которая в целом отражает текущую ситуацию. В качестве саундтрека к посту рекомендуется Little Big, “Life in da trash”.

Сразу начну с того, что я не призываю никого бежать из Мессенджера-который-нельзя-называть. Совсем даже наоборот. Просто спать гораздо спокойнее, когда одно облако у тебя забэкаплено в другом облаке. А то и облака периодически падают на грешную землю, а терять годы переписки очень обидно. Да и друг меня спросил, как сделать бэкап, а я с ходу не нашёл внятной инструкции.
Предупреждаю сразу - для бэкапа вам потребуется Linux, или хотя бы виртуалка с ним. При наличии рук можно и на Mac OS, и может даже можно на том огрызке, что нынче встроен в Windows - но я ничего не гарантирую.
Поехали!
Вы как-нибудь задумывались, сколько версий одной и той же библиотеки затягивает ваша клиентская или серверная сборка? Мне вот в какой-то момент стало интересно. Навскидку найти для этого готовый инструмент не получилось, а смотреть глазами package-lock слишком утомительно. Как мы знаем - в любой непонятной ситуации нужно писать свой npm пакет, поэтому я именно это и сделал… Дальше в посте я рассмотрю результат анализа живого проекта и сделаю пару спорных выводов.
Ну и никак нельзя обойтись без этой классической картинки:
Не хотелось писать статью про настройку впн, потому что их и без меня в интернете тысячи - выбирай на вкус и цвет.
Просто хотел напомнить просто несколько простых вещей, которые вызывают много недоразумений и вопросов. Понимаю, что на статью не тянет, но очень хочется до вас достучаться, а других способов в рунете особо и нет.
Подозреваю, что многие из читателей этой публикации в детстве не носили с собой мобильный телефон, или начали носить его только в старших классах - как ни странно, обыденные на сегодняшний момент мобильники появились не так давно. И даже после их появления в течение долгого времени мобильные телефоны были огромными и дорогими, и позволить их себе могли только серьёзные дядьки. Но на дворе 2018 год, и младшеклассники вовсю пользуются смартфонами.
Конечно, дети разные, и проблемы у всех в связи с этим возникают разные. У кого-то проблем вообще не возникает, и я могу только порадоваться за этих людей. Лучше всего, если получается договориться с ребёнком о разумном использовании телефона - но этот случай мы рассматривать не будем как довольно очевидный (договорились - молодцы). Будем рассматривать тот случай, когда нужно выдавать ребёнку смартфон, но при этом технически ограничивать его применение.

Давным давно, когда я был молод и писал сайты на PHP, я написал SEO плагин для маскировки внешних ссылок для Wordpress. Поскольку с воображением у меня плохо, то назвал его WP-NoExternalLinks. За всю историю у него было 360.000 установок и, кажется, до 50.000 активных установок.
Дальше я расскажу, каким именно образом он попал в недобросовестные руки и был злонамеренно использован - но для этого придётся немного погрузиться в его историю и обстановку разработки. Сразу предупрежу, что эта история абсолютно реальная.

Недавно была прекрасная публикация “Рассказ о том, как я ворую номера кредиток и пароли у посетителей ваших сайтов”, на которую я переводил ответ. Автор недавно опубликовал вторую часть, но, подозреваю, что перевода не будет - там предлагается решать проблему прекрасными способами вроде перевода важных элементов ввода “в отдельный iframe” или “на особые страницы без стороннего javascript”. На этом месте те, кто повёлся на первую статью, должны бы усомниться в адекватности автора - и низкий (относительно предыдущей) рейтинг новой статьи это показывает.
UPD: перевели таки.
Тем не менее, проблема сторонних зависимостей есть, и решать её как-то нужно. Причём стоит она в равной степени в любой экосистеме, где используются сторонние зависимости. В комментариях к прошлому посту уже запрашивали какой-нибудь вариант решения, и я хочу представить один из них - инструмент под названием snyk.
![]()
Моя карьера началась с написания программ для мобильных устройств. Я изучал C и Objective-C, чтобы работать с устройствами на iOS. У меня был чёткий контроль над программным обеспечением, я учился тому, как правильно работать с памятью, и проводил долгие часы за отладкой багов, которые возникали из-за моей небрежности (это было ещё до ARC). Я развивался с уклоном в сторону iOS, а так же так же начал изучать Java (и совсем недавно приступил к Kotlin) для перехода на Android.