9 лет в монолите на Node.JS

Неделю назад я выступал на митапе по Node.JS, и многим обещал выложить запись выступления. Уже потом я понял, что мне не удалось вместить в регламентированные полчаса некоторые интересные факты. Да и сам я больше люблю читать, а не смотреть и слушать, поэтому решил выложить выступление в формате статьи. Впрочем, видео тоже будет в конце поста в разделе ссылок.
Рассказать я решил про набившую оскомину тему - жизнь в монолите. Об этом на хабре уже есть сотни статей, тысячи копий сломаны в комментах, истина давно погибла в спорах, но… Дело в том, что у нас в OneTwoTrip есть весьма специфический опыт, в отличие от многих людей, которые пишут про некие архитектурные паттерны в вакууме:
- Во-первых, нашему монолиту уже 9 лет.
- Во-вторых, всю жизнь он провёл под хайлоадом (сейчас это 23 млн запросов в час).
- А в NaN-ых, мы пишем наш монолит на Node.JS, который за эти 9 лет изменился до неузнаваемости. Да, мы начинали писать на ноде в 2010, безумству храбрых поём мы песню!
Так что всякой специфики и реального опыта у нас довольно много. Интересно? Поехали!
Дисклеймер раз > Данная презентация отражает лишь частное мнение ее автора. Оно может совпадать с позицией компании «OneTwoTrip», а может и не совпадать. Тут уж как повезет. Я работаю техлидом одной из команд компании и не претендую на объективность или выражение чьего-то мнения кроме своего.
Дисклеймер два > Данная статья описывает исторические события, и на текущий момент всё совсем не так, так что не пугайтесь.
0. Как же так вышло
Тренд запроса слова “microservice” в google:
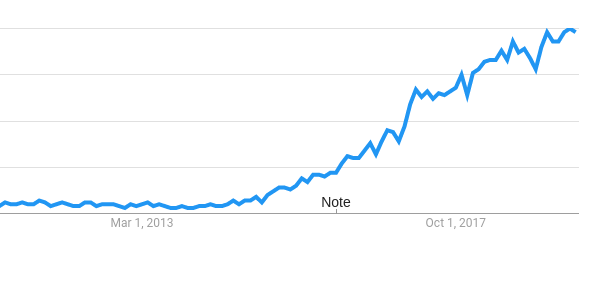 Всё очень просто - девять лет назад никто и не знал про микросервисы. Так что начали мы писать, как и все - в монолите.
Всё очень просто - девять лет назад никто и не знал про микросервисы. Так что начали мы писать, как и все - в монолите.
1. Боль в монолите
Здесь я опишу проблемные ситуации, которые у нас случались за эти 9 лет. Часть из них решена, часть была обойдена хаками, часть просто потеряла актуальность. Но память о них, как боевые шрамы - уже никогда не оставит меня.
1.1 Обновление связных компонентов
 Тот самый случай, когда синергия - это зло. Потому что любой компонент был переиспользован по несколько сотен раз, и если была возможность использовать его криво - то она не была упущена. Любое действие может вызвать абсолютно непредсказуемые эффекты, и не все из них отслеживаются юнитами и интеграционными тестами. Помните историю про швабры, вентилятор и воздушный шар? Если нет, то загуглите. Она является лучшей иллюстрацией кода в монолите.
Тот самый случай, когда синергия - это зло. Потому что любой компонент был переиспользован по несколько сотен раз, и если была возможность использовать его криво - то она не была упущена. Любое действие может вызвать абсолютно непредсказуемые эффекты, и не все из них отслеживаются юнитами и интеграционными тестами. Помните историю про швабры, вентилятор и воздушный шар? Если нет, то загуглите. Она является лучшей иллюстрацией кода в монолите.
1.2 Миграция на новые технологии
Хочешь Express? Линтер? Другой фреймворк для тестов или моков? Обновить валидатор или хотя бы lodash? Обновить Node.js? Извини. Для этого придётся править тысячи строк кода.
Многие говорят про преимущество монолита, которое состоит в том, что любая правка - это атомарный коммит. Умалчивают эти люди об одном - эта правка никогда не будет сделана.
Знаете старую шутку про семантическое версионирование?
> the real semantics of semantic versioning: > > major = a breaking change > minor = a minor breaking change > patch = a little-bitty breaking change
А теперь представьте, что в вашем коде почти наверняка всплывёт любой little-bitty breaking change. Нет, жить с этим можно, и мы таки периодически собирались с силами и мигрировали, но это правда было очень тяжело. Очень.
1.3 Релизы
Здесь надо сказать о некоторой специфике нашего продукта. У нас есть огромное количество внешних интеграций, и различных веток бизнес логики, которые всплывают по отдельности довольно редко. Я очень завидую продуктам, которые фактически выполняют все ветви своего кода за 10 минут в продакшне, но у нас не тот случай. Путём проб и ошибок, мы нашли для себя оптимальный релизный цикл, который минимизировал количество ошибок, которые дойдут до конечных пользователей:
- релиз собирается и за полдня проходит интеграционные тесты
- дальше он день лежит под внимательным присмотром на стейдже (для 10% пользователей)
- затем лежит ещё день на продакшне под ещё более внимательным присмотром.
- И только после этого мы даём ему зелёный свет в мастер.
Так как мы любим наших коллег и не релизим по пятницам, то в итоге это означает, что релиз уходит в мастер примерно 1.5-2 раза в неделю. Что приводит к тому, что в релизе может быть по 60 задач и больше. такое количество вызывает мердж конфликты, внезапные синергетические эффекты, полную загруженность QA на разборе логов, и прочие печали. В общем, очень тяжело нам было релизить монолит.
1.4 Просто очень много кода
Казалось бы, количество кода не должно иметь принципиального значения. Но… На самом деле нет. В реальном мире это:
- Более высокий порог вхождения
- Огромные артефакты сборки на каждую задачу
- Долгие CI процессы, включая интеграционные тесты, юнит тесты, и даже линтинг кода
- Медленная работа IDE (на заре развития Jetbrains мы не раз шокировали их своими логами)
- Сложный контекстный поиск (не забывайте, у нас нет статической типизации)
- Сложность поиска и удаления неиспользуемого кода
1.5 Отсутствуют владельцы кода
Очень часто возникают задачи с непонятной сферой ответственности - например, в смежных библиотеках. А исходный разработчик мог уже перейти в другую команду, или вообще уйти из компании. Единственный способ найти ответственного в таком случае - административный произвол - взять и назначить человека. Что не всегда приятно и разработчику и тому, кто это делает.
1.6 Сложность отладки
Потекла память? Выросло потребление CPU? Захотелось построить флейм графы? Извини. В монолите одновременно происходит столько всего, что локализовать какую-то проблему становится безумно сложно. Например, понять, какая из 60 задач при выкатке в продакшн вызывает повышенное потребление ресурсов (хотя локально, на тестовых и стейджинг средах это не воспроизводится) - почти нереально.
1.7 Один стек
С одной стороны, хорошо, когда все разработчики “говорят” на одном языке. В случае JS получается, что даже Backend с Frontend разработчиками понимают друг друга. Но…
- Серебряной пули не существует, и для некоторых задач иногда хочется использовать что-нибудь другое. Но у нас монолит, и нам некуда воткнуть других разработчиков.
- Мы не можем просто взять по рекомендации хорошую команду, которая пришла к нам по совету друзей - нам её некуда деть.
- Со временем мы упираемся в то, что на рынке просто не хватает разработчиков на нужном стеке.
1.8 Много команд с разным представлением о счастье
Если у вас есть два разработчика, то у вас уже есть два разных представления о том, какой самый лучший фреймворк, какие надо соблюдать стандарты линтинга, использовать библиотеки, и так далее. Если у вас есть десять команд, в каждой из которых по несколько разработчиков, то это просто катастрофа. И способа решения всего два - или “демократический” (каждый делает что хочет), или тоталитарный (стандарты насаждаются свыше). В первом случае страдает качество и стандартизация, во втором - люди, которым не дают реализовать своё представление о счастье.
2. Плюсы монолита
Конечно, есть в монолите и какие-то плюсы, которые могут быть разными для разных стеков, продуктов и команд. Конечно, их гораздо больше, чем три, но за все возможные я отвечать не буду, только за те, которые были актуальны для нас.
2.1 Простота развёртывания
Когда у тебя есть один сервис, то поднять и тестировать его гораздо проще, чем десяток сервисов. Правда, плюс этот актуален только на начальном этапе - например, можно поднять тестовую среду, и использовать все сервисы, кроме разрабатываемых, из неё. Или из контейнеров. Или как угодно ещё.
2.2 Нет оверхеда на передачу данных
Довольно сомнительный плюс, если у тебя не хайлоад. Но у нас именно такой случай - поэтому затраты на транспорт между микросервисами для нас заметны. Как бы ты ни старался быстро это сделать, хранить и передавать всё в оперативной памяти быстрее всего - это очевидно.
2.2 Одна сборка
Если нужно откатиться на какой-то момент в истории, то сделать это с монолитом реально просто - взял и откатился. В случае микросервисов приходится подбирать совместимые между собой версии сервисов, которые использовались друг с другом в конкретный момент времени, что не всегда может быть просто. Правда, это тоже решается при помощи инфраструктуры.
3. Мнимые плюсы монолита
Сюда я отнёс все те вещи, которые обычно считают плюсами, но с моей точки зрения ими не являются.
3.1 Код - это и есть документация
Часто слышал такое мнение. Но обычно его придерживаются начинающие разработчики, которые не видели файлов в десятки тысяч строк кода, написанных годы назад ушедшими людьми. Ну и почему-то чаще всего этот пункт приводят в плюс сторонники монолита - мол, нам не нужны никакие документации, у нас нету ни транспорта, ни апи - всё в коде, легко и понятно. Не буду спорить с этим утверждением, просто скажу, что не верю в него.
3.2 Нет разных версий библиотек, сервисов и API. Нет разных репозиториев.
Да. Но нет. Потому что на второй взгляд ты понимаешь, что сервис существует не в вакууме. А среди огромного количества другого кода и продуктов, с которыми интегрируется - начиная от сторонних библиотек, продолжая версиями серверного ПО, и не заканчивая внешними интеграциями, версией IDE, CI инструментов, и так далее. А как только ты понимаешь, сколько различных версионируемых вещей опосредовано в себя включает твой сервис, сразу становится понятно, что этот плюс - всего лишь демагогия.
3.3 Проще мониторинг
Проще. Потому что у тебя есть, грубо, говоря, один дашборд, вместо нескольких десятков. Но сложнее, и порой даже невозможен - потому как ты не можешь декомпозировать свои графики по различным частям кода, и имеешь только среднюю температуру по больнице. В целом, я уже сказал всё в пункте про сложность отладки, просто уточню, что эта же сложность распространяется и на мониторинг.
3.4 Проще соблюдать единые стандарты
Да. Но, как я уже писал в пункте про множество команд с представлением о счастье - стандарты или навязываются тоталитарно, или ослабляются почти до отсутствия оных.
3.5 Меньше вероятность дублирования кода
Странное мнение о том, что в монолите код не дублируется. Но встречал его довольно часто. На моей же практике выходит, что дублирование кода зависит исключительно от культуры разработки в компании. Если она есть - то общий код выделяется во всевозможные библиотеки, модули и микросервисы. Если же её нет - то и в монолите будет копи-пейст по двадцать раз.
4. Плюсы микросервисов
Теперь напишу о том, что мы получили после миграции. Опять же - это реальные выводы из реальной ситуации.
4.1 Можно делать гетерогенную инфраструктуру
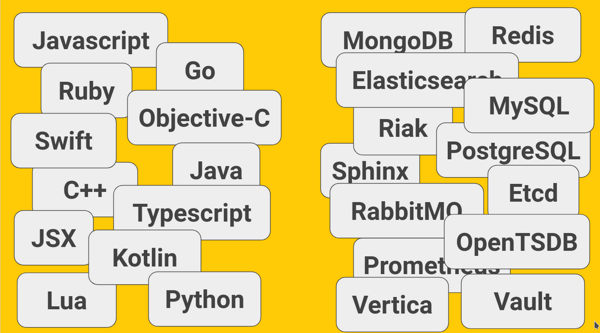
Теперь мы можем писать код на cтеке, который оптимален для решения конкретной задачи. И рационально использовать любых хороших разработчиков, которые к нам попали. Для примера - вот примерный список технологий, которые есть у нас на данный момент:
4.2 Можно делать много частых релизов
Теперь мы можем делать много небольших независимых релизов, и они получаются проще, быстрее, и не доставляют боли. Когда-то у нас была всего одна команда, а сейчас их уже 18. Если бы они все остались в монолите, то его бы, наверное, порвало. Или людей, которые за него отвечают…
4.3 Проще делать независимые тесты
Мы сократили время интеграционных тестов, которые теперь тестируют только то, что реально изменилось, и при этом не боимся эффектов внезапной синергии. Конечно, пришлось для начала походить по граблям - например, научившись делать обратно совместимые API - но со временем всё устаканилось.
4.4 Легче внедрять и тестировать новые фичи
Теперь мы открыты для экспериментов. Любые фреймворки, стеки, библиотеки - всё можно попробовать, и в случае успеха продвигать дальше.
4.5 Можно обновлять что угодно
Можно обновлять версию движка, библиотек, да чего угодно! В рамках небольшого сервиса, найти и поправить все breaking changes - дело минут. А не недель, как было раньше.
4.6 А можно не обновлять
Как ни странно, это одна из наиболее крутых фич микросервисов. Если у тебя есть стабильно работающий код, то ты можешь его просто заморозить, и забыть про него. И тебе никогда не придётся его обновлять, например, для того, чтобы запустить код продукта на новом движке. Продукт сам по себе работает на новом движке, а микросервис продолжает жить как жил. Мухи с котлетами наконец можно есть раздельно.
5 Минусы микросервисов
Конечно, без ложки дёгтя не обошлось, и совершенного решения, чтобы только сидеть и получать зарплату, не вышло. С чем же мы столкнулись:
5.1 Нужна шина для обмена данными и внятное логирование.
Взаимодействие сервисов по HTTP это классическая модель, и в целом даже рабочая, при условии, что между ними есть логирующие и балансирующие прослойки. Но лучше иметь более внятную шину. Кроме того, следует думать о том, как собирать и объединять между собой логи - иначе у вас на руках будет просто каша.
5.2 Нужно следить за тем, что делают разработчики
В целом, это следует делать всегда, но в микросервисах у разработчиков заведомо больше свободы, что порой может породить такие вещи, от которых Стивен Кинг покрылся бы мурашками. Даже если внешне кажется, что сервис работает - не забывайте, что должен быть человек, который следит за тем, что у него внутри.
5.3 Нужна хорошая команда DevOps, чтобы всем этим управлять.
Почти любой разработчик может так или иначе развернуть монолит и выкладывать его релизы (например, по FTP или SSH, видел я такое). Но с микросервисами появляются всякие централизованные сервисы сбора логов, метрик, дашборды, шефы для управления конфигами, волты, дженкинс, и прочее добро, без которого в целом жить можно - но плохо и непонятно зачем. Так что для управления микросервисами нужно иметь хорошую DevOps команду.
5.4 Можно попытаться словить хайп и выстрелить себе в ногу.
Наверное, это главный минус архитектуры и её опасность. Очень часто люди вслепую идут за трендами и начинают внедрять архитектуру и технологию, не понимая её. После чего всё падает, они путаются в полученной каше, и пишут статью на хабр “как мы переехали с микросервисов в монолит”, например. В общем - переезжайте, только если вы знаете, зачем вы это делаете, и какие проблемы вы решите. И какие получите.
6 Хаки в монолите
Некоторые количество хаков, которые позволяли нам жить в монолите чуть лучше и чуть дольше.
6.1 Линтинг
Внедрение линтера в монолите - не такая простая задача, как кажется на первый взгляд. Конечно, можно сделать строгие правила, добавить конфиг, и…. Ничего не изменится, все просто выключат линтер, потому что половина кода станет красным.
Для постепенного внедрения линтинга мы написали простую надстройку над eslint - slowlint, который позволяет сделать одну простую вещь - содержать список временно игнорируемых файлов. В результате:
- Весь некорректный код подсвечивается в IDE
- Новые файлы создаются по правилам линтинга, иначе CI их не пропустит
- Старые постепенно правятся и уходят из исключений
За год удалось привести под единый стиль примерно половину кода монолита, то есть почти весь активно дописываемый код.
6.2 Доработки юнит тестов
Когда-то юнит тесты выполнялись у нас по три минуты. Разработчики не хотели ждать столько времени, так что всё проверялось только в CI на сервере. Через некоторое время разработчик узнавал, что тесты упали, чертыхался, открывал ветку, возвращался к коду… В общем, страдал. Что мы с этим сделали:
- Для начала начали запускать тесты многопоточно. У яндекса есть вариант многопоточной mocha, но у нас он не взлетел, так что сами писали простую обёртку. Тесты стали выполняться в полтора раза быстрее.
- Затем мы переехали с 0.12 ноды на 8ую (да, процесс сам по себе тянет на отдельный доклад). Принципиального выигрыша в производительности на продакшне это, как ни странно, не дало, но тесты стали выполняться на 20% быстрее.
- А дальше мы таки сели отлаживать тесты и оптимизировать их по отдельности. Что дало наибольший прирост в скорости.
В общем, на текущий момент юнит тесты запускаются в препуш хуке и отрабатывают за 10 секунд, что довольно комфортно и позволяет их запускать без отрыва от производства.
6.3 Облегчение веса артефакта
Артефакт монолита со временем стал занимать 400 мегабайт. С учётом того, что он создаётся на каждый коммит, суммарно объёмы получались довольно большие. С этим нам помог модуль diarrhea, форк модуля modclean. Мы удаляли из артефакта юнит тесты и чистили его от различного мусора вроде ридми файлов, тестов внутри пакетов, и так далее. Выигрыш составил порядка 30% от веса!
6.4 Кэширование зависимостей
Когда-то установка зависимостей при помощи npm занимала столько времени, что можно было не только попить кофе, но и, например, испечь пиццу. Поэтому сначала мы пользовались модулем npm-cache, который форкали и немного допиливали. Он позволял сохранять зависимости на общем сетевом диске, с которого его потом брали все остальные билды.
Потом мы задумались о воспроизводимости сборок. Когда у тебя монолит, то смена транзитивных зависимостей - бич божий. Учитывая то, что мы тогда сильно отставали по версии движка, смена какой-нибудь зависимости пятого уровня запросто ломала нам всю сборку. Поэтому мы начали использовать npm-shrinkwrap. С ним было уже проще, хотя мерджить его изменения - удовольствие для сильных духом.
А дальше наконец появился package-lock и прекрасная команда npm ci - которая выполнялась с лишь чуть меньшей скоростью, чем установка зависимостей с файлового кеша. Поэтому мы начали пользоваться только ей, и перестали хранить сборки зависимостей. В этот день я принёс на работу несколько коробок пончиков.
6.5 Распределение очерёдности релизов.
А это скорее административный хак, а не технический. Изначально я был против него, но время показало, что второй техлид был прав и вообще молодец. Когда релизы распределили по очереди между несколькими командами, стало понятнее, где именно появляются ошибки, и что важнее - каждая команда чувствовала свою ответственность за скорость, и старалась решать проблемы и выкатываться как можно быстрее.
6.6 Удаление мёртвого кода
В монолите очень страшно удалять код - никогда не знаешь, где на него могли завязаться. Поэтому чаще всего он просто остаётся лежать сбоку. Годами. А даже мёртвый код приходится поддерживать, не говоря уже о путанице, которую он вносит. Поэтому со временем мы начали использовать require-analyse для поверхностного поиска мёртвого кода, и интеграционные тесты плюс запуск в режиме проверки покрытия - для более глубокого поиска.
7 Распил монолита
Почему-то многие считают, что для того, чтобы перейти на микросервисы, надо забросить свой монолит, написать рядом с нуля кучу микросервисов, разом всё это запустить - и будет счастье. Но эта модель… Хмм… Чревата тем, что вы ничего не сделаете, и только потратите кучу времени и денег на написание кода, который придётся выкинуть.
Предлагаю другой вариант, который мне кажется более рабочим, и который был реализован у нас:
- Начинаем писать новые сервисы в микросервисах. Обкатываем технологию, прыгаем по граблям, понимаем, хотим ли вообще это делать.
- Выделяем код в модули, библиотеки, или что у вас там используется.
- Выделяем из монолита сервисы.
- Выделяем из сервисов микросервисы. Без спешки и по одному.
8 И напоследок

Под конец я решил оставить самое главное.
Помните:
- Вы не Google
- Вы не Microsoft
- Вы не Facebook
- Вы не Yandex
- Вы не Netflix
- Вы не OneTwoTrip
Если что-то работает в других компаниях - абсолютно не факт, что это принесёт пользу вам. Если пытаться вслепую копировать опыт других компаний со словами “у них же работает” - то это скорее всего закончится плохо. Каждая компания, каждый продукт и каждая команда - уникальна. То что работает для одних - не будет работать для других. Не люблю говорить очевидные вещи, но слишком много людей начинают строить карго-культ вокруг других компаний, слепо копируя подходы, и погребают себя под фальшивыми ёлочными игрушками. Не делайте так. Экспериментируйте, пробуйте, вырабатывайте те решения, которые оптимальны именно для вас. И только тогда всё получится.
Полезные ссылки:
- Мой доклад в видео формате
- Полный плейлист с митапа по Node.JS